
1. 복제본 Auto Scaling

작동 방식
- 읽기 요청이 증가하여 Aurora 인스턴스의 CPU 사용량이 높아지면 복제본 Auto Scaling이 활성화됩니다.
- 자동으로 새로운 읽기 복제본(Read Replica)을 생성하여 읽기 트래픽을 분산
- 결과적으로 전체적인 CPU 사용량을 줄이고 읽기 성능을 향상시킴
- 포인트:
- 읽기 트래픽 증가 시 자동으로 복제본 추가
- 로드 밸런싱은 Reader Endpoint를 통해 이루어짐
- 포인트:
2. 사용자 지정 엔드포인트 (Custom Endpoint)

작동 방식:
- 복제본 중 일부(예: 더 강력한 사양의 인스턴스)를 특정 작업(예: 분석 쿼리)에 사용하도록 정의
- 사용자 지정 엔드포인트(Custom Endpoint)를 만들어 해당 복제본에 연결
- 리더 엔드포인트는 계속 사용할 수 있지만, 특정 작업에 대해 사용자 지정 엔드포인트를 선호
- 포인트:
- 특정 Aurora 복제본에 대해 별도 엔드포인트를 정의 가능
- 분석 쿼리 등 특정 작업에 적합한 복제본을 선택적으로 활용
- 포인트:
3. Aurora Serverless

작동 방식:
- 데이터베이스의 용량이 자동으로 조정되며, 간헐적이거나 예측 불가능한 워크로드에 적합
- 클라이언트는 Aurora가 관리하는 프록시 플릿(Proxy Fleet)과 통신하며, Aurora는 필요에 따라 인스턴스를 자동 생성/삭제
- 실제 사용량에 따라 초 단위로 비용 지불, 비용 효율적
- 포인트:
- 간헐적/예측 불가능한 워크로드에 최적
- 용량 계획이 필요 없음, 초당 사용량에 따라 비용 청구
- 포인트:
4. Aurora Global Database
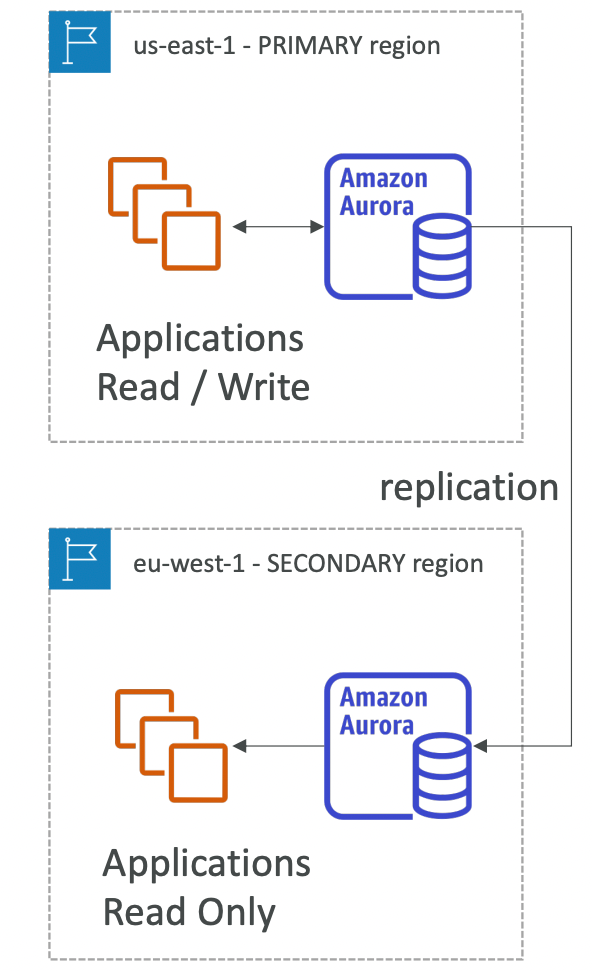
작동 방식:
- 하나의 기본 리전에서 읽기와 쓰기 작업을 수행
- 최대 5개의 보조 리전에 데이터를 복제하며, 각 리전은 최대 16개의 읽기 복제본을 가질 수 있음
- 보조 리전의 응답 지연 시간은 1초 이하
- 기본 리전에서 장애가 발생하면, 1분 이내에 보조 리전을 쓰기 가능 상태로 승격하여 복구
- 포인트:
- 리전 간 데이터 복제 속도는 평균 1초 이하
- 글로벌 데이터베이스는 재해 복구(Disaster Recovery)에 적합하며, 읽기 지연을 줄임
- 보조 리전을 읽기 전용으로 활용, 필요 시 쓰기 리전으로 승격 가능
- 포인트:
5. Aurora와 기계 학습 (Machine Learning Integration)

통합 서비스:
- Amazon SageMaker: 기계 학습 모델 사용
- Amazon Comprehend: 감정 분석에 사용
작동 방식:
- Aurora는 SQL 쿼리로 기계 학습 기반 예측을 수행
- 예: 추천 상품은 무엇인가? 쿼리 실행 → Aurora가 데이터를 SageMaker 또는 Comprehend로 전송->결과를 SQL 쿼리로 반환
- 포인트:
- Aurora는 SageMaker와 Comprehend와의 통합을 지원
- SQL 쿼리만으로 기계 학습 기능 활용 가능
요약
- 복제본 Auto Scaling: 읽기 요청 증가 시 자동으로 복제본 생성, CPU 사용량 감소
- 사용자 지정 엔드포인트: 특정 복제본에 대해 엔드포인트를 정의하여 작업 분리
- Aurora Serverless: 자동으로 용량 조정, 간헐적 워크로드에 적합, 비용 효율적
- Aurora Global Database: 리전 간 데이터 복제 지연 1초 이하, 1분 이내 장애 복구
- Aurora와 기계 학습: SageMaker 및 Comprehend와 통합, SQL 쿼리로 예측 가능
'AWS' 카테고리의 다른 글
| RDS & Aurora - 백업과 모니터링 요약 정리 (0) | 2024.12.01 |
|---|---|
| RDS와 Aurora의 백업, 복원, 복제 기능 정리 (0) | 2024.12.01 |
| Aurora DB Cluster 작동 방식 정리 (0) | 2024.11.30 |
| Aurora High Availability and Read Scaling (Aurora의 고가용성과 읽기 확장성) (0) | 2024.11.30 |
| Amazon Aurora (0) | 2024.11.30 |